This is a section from a nonfiction book I'm writing (...I guess this public announcement will now pressure me to finish it and find a publisher 😬). Thanks Anna Pryslopska for initiating the interesting Twitter discussion!
It’s common knowledge that Americans use the unique date format mm-dd-yyyy, in which the month appears before the day, differently from the rest of the world. There is no clear answer to why that is, but some hypothesize that this format was used in the UK, brought to the US by the Brits, and later changed in the UK to the European format dd-mm-yyyy. This is certainly a cause for confusion, which is almost inevitable when a date signifies July 4th for one person and April 7th for the other. With that said, it may also be useful in some very specific scenarios. A young colleague who travelled to a conference in the US a few weeks before his 21st birthday on July 4th, had successfully purchased alcohol by misleading the bartender into thinking his birthday, which was printed on a non-US passport, was April 7th.
I was more surprised to learn that Americans use a 12 hour clock (with AM and PM distinctions as needed) rather than the 24 hour clock. I think part of the reason it was less noticeable, is that both clocks are acceptable outside the US. It wasn’t until I texted an American friend, during a conference, that I will meet him at 18:00 next to the escalator, which made him chuckle and inform me I was using “military time”.
It was the same friend that only a couple of years earlier I was supposed to go sightseeing with on the day after the conference ended, and in the morning he texted me that we can meet in the afternoon. I was surprised, because my interpretation of “afternoon”, based on the norm associated with its literal translation to Hebrew, means around 4 or 5 pm, which seemed quite a late hour to begin sightseeing. He, of course, literally meant any time after 12 pm, which is a reasonable time to leave your hotel room after a week of exhausting conferencing.
Indeed, people interpret time expressions with some variation from each other. A 2002 study by the University of Aberdeen analyzed human-written weather forecasts along with the weather data they described. The study found significant individual differences between forecasters in the interpretation of some time phrases such as “by evening”, but full agreement on other expressions such as “midday”.
I couldn’t find any study regarding the cultural differences in interpretation of time expressions, so I conducted my own. I built a very simple survey with the following questions:
Where are you from, or where have you lived most of your life?
What is the range of time you consider as morning (or the equivalent of morning in your native language)?
What is the range of time you consider as noon (or the equivalent of noon in your native language)?
What is the range of time you consider as afternoon (or the equivalent of afternoon in your native language)?
What is the range of time you consider as evening (or the equivalent of evening in your native language)?
What is the range of time you consider as night (or the equivalent of night in your native language)?
I published the survey on Amazon Mechanical Turk, a crowdsourcing platform that enables recruiting workers to perform discrete tasks. To get answers from a range of countries, I published several batches of questionnaires, each time limiting them to workers from specific regions of the world.
Before I dive into the results, I would like to point out that this study was not conducted with my usual level of scientific rigour, mostly for budgetary reasons. In less subtle words, I did not conduct this experiment for my work, thus couldn’t pay for it with my research budget and paid with my own money, so I went cheap. Because my budget was limited, I collected only 349 answers, which means that for most countries I collected only a handful of answers or no answers at all, making conclusions about those countries less statistically well-supported. Moreover, some countries have many more Mechanical Turk workers than others, so I ended up collecting a very uneven number of responses from each country.
In addition, I live in the Pacific time zone (PST), and the time I published the batches affected the distribution of countries of workers who responded to the survey. For example, I thoughtlessly published the North American survey at 4 pm PST on a Friday, which likely meant most of the answers came from people living in the west coast. People living in countries when it was night time when the survey was made available were either not well represented or worse - distorted the data. Think of a person answering a survey at 2 am their time, do you really trust them as representative of their culture with respect to time? Go to sleep, dude.
So, if you would still like to discover the results of my very unscientific study, here they are. This was the country distribution:
Since the US is dominant in the survey, let’s first analyze the results received among participants in the US. The following figure presents the average start and end times for each time expression, along with error bars to mark the standard deviation, that measures the dispersion of the data relative to the average.
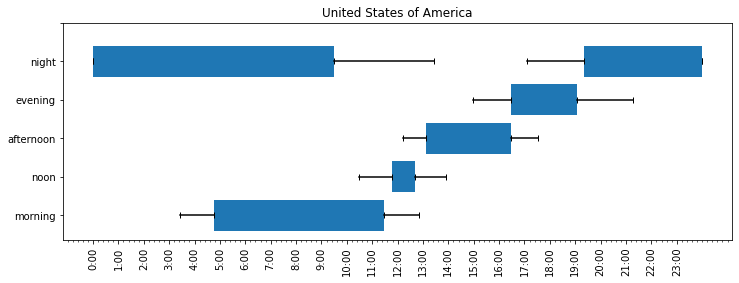
Americans considered morning on average to span from 4:45 to 11:27 am, noon from 11:47 am to 12:41 pm, afternoon from 1:06 pm to 4:27 pm, evening from 4:27 to 7:04 pm, and night from 7:19 pm to 9:30 am. If you’re wondering about the contradiction of the early morning start time (4:45 am) and the late night end time (9:30 am), the error bars can explain this discrepancy. The night end time data had the largest standard deviation, with many outliers such as people who considered the night to end at 11:59 pm for some reason. A more informative statistic that is less sensitive to outliers is the median. The median is the time that is the same or later than what half of the people would consider as the end of the night, and the same or earlier than what half of the people would consider as the end of the night. It was much earlier, at 5:45 am.
At this point, I’ve already empirically shown that Americans indeed consider “noon” as a very narrow time slot around 12 pm, although a small number of them were extremely early risers for whom 10 am already feels like noon, and some considered noon to end as late as 2 pm. Another observation that stands out for me here is the early evening beginning. It explains the early US dinner. If the evening starts at 4:30 pm, “The Cadillac” episode in season 7 of Seinfeld seems slightly less crazy. In this episode, Jerry visits his retired parents in Florida. They are getting ready to go to dinner at 4:30, to make it to the early-bird rate. Jerry says he can’t “force feed himself a steak at 4:30” and convinces them to wait for the regular priced dinner at 6.
Even if you treat the retiree population in Florida as an outlier, Dinner in the US is eaten rather early, around 6pm. I’ve had work dinners at 5:30pm as well. I’ve heard about restaurants that are so busy that you must book a table for dinner… unless you are willing to eat as late as 8 pm. Needless to say, 8 pm seems like a perfectly good time for dinner to me. I’ve often used “dinner time” as an example for temporal commonsense, e.g. “dinner is typically eaten at around 8 pm”. But giving it a second thought, I realize this is rather culture-specific. On trips to some countries in Europe we wandered around hungry at 9 pm, not finding where to eat because all the restaurants were already closed. In other countries it’s customary to eat very late, such as in Spain.
What makes the dinner time convention more confusing is that the meaning of the word dinner is not exactly “the evening meal”. Today, people typically use “dinner” and “supper” interchangeably to refer to the last meal of the day. However, Merriam-Webster classifies supper as a lighter meal, or “the evening meal especially when dinner is taken at midday”, while dinner is "the principal meal of the day" regardless of its time.
In 2019, my birthday happened to be on Thanksgiving. We tried to book a table in a restaurant for dinner. The options were limited because many restaurants were closed for the holiday and others only served Thanksgiving dinner. I don’t eat chicken, nor am I a fan of holiday food (blatantly generalizing from my experience with Jewish holidays). By the time we found a restaurant that serves its usual menu, they had no available tables for dinner. Right after hanging up the phone I had second thoughts about the way I phrased the question. I called again and asked whether they had available tables at 8 pm. They did. We had a great meal. It was only intuition that made me recheck, but when I dug deep into this, I learned the difference between dinner and supper, and I found out that Thanksgiving dinner is often eaten at around 2 to 4 pm, hours that I would consider lunch time. This ACL 2019 paper, in which textual mentions and their corresponding grounded values were automatically extracted from a large English text corpus, also supports this observation. In a figure showing the time of the day in which meals are typically eaten, dinner seemed to start according to some people as early as 1 pm.
Before all this talk about dinner makes me hungry, I will get back to the survey results. So how is the US different from the rest of the world? We don’t have enough data for a fine-grained analysis country-by-country, but we can group countries by continent, for example looking at all answers from Europe.
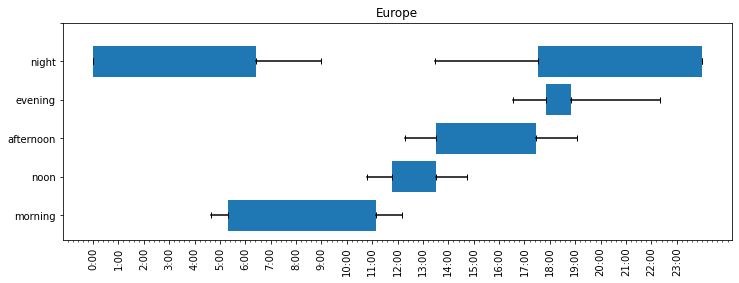
In Europe, the average morning was between 5:19 and 11:08 am, noon between 11:47 am and 1:30 pm, afternoon between 1:31 and 5:28 pm, evening between 5:51 and 6:50 pm, and night from 5:32 pm to 6:26 am. I was quite surprised by how early people considered the night to start, and in particular the intersection between the evening and night. I’ve heard people saying “good night” at 5 pm in the US, but expected Europe to party harder. Luckily, I allowed the survey respondents to add a free-text comment, and thankfully, many of them did. Two Spanish workers commented that in Spanish, there is no distinction between afternoon and evening, and that Spanish doesn't really have a word for evening. The word “tarde” (afternoon) is used to describe the range of hours from 1 pm to 8 pm, after which it is “noche” (night).
There are two other countries with enough responses for a meaningful statistical analysis: India and Brazil. Here is the same figure, for India:
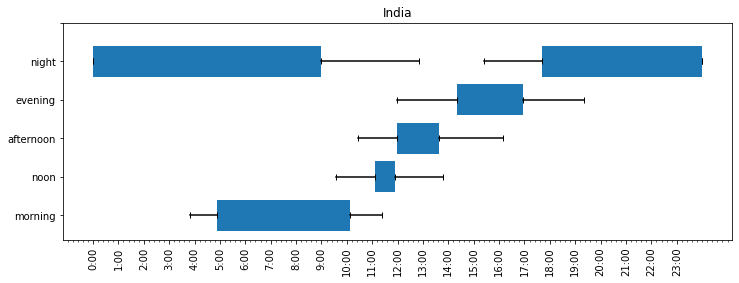
In India, morning starts at 4:53 and ends at 10:05 am, noon starts at 11:14 am and ends at 11:55 pm, afternoon is between 12 and 1:37 pm, evening between 2:21 and 4:56 pm, and night from 5:45 pm to 8:54 am. Largely, all time expressions referred to earlier times than in the US, with the night spanning over 15 of the 24 hours.
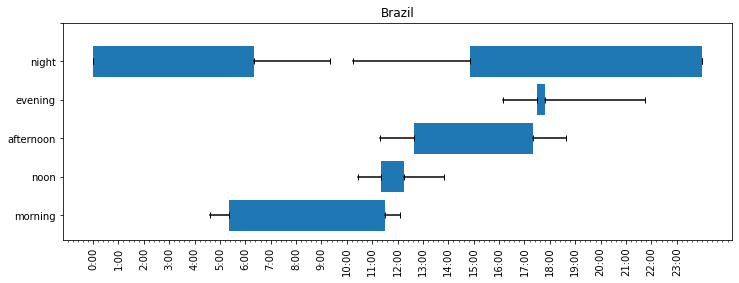
In Brazil, morning is between 5:21 and 11:29 am, noon is between 11:20 am and 12:16, afternoon from 12:39 to 5:20 pm, evening from 5:28 to 5:49 pm, and night from 2:50 pm to 6:20 am. Again, the evening was swallowed by the night, and again, the comments explain it. First, many commented that there is no concept of evening in Brazil. One person elaborated and said that it gets dark early, and once it’s dark, it is already considered night. In addition, some people mentioned that there is no concept of “noon” either.
My own interpretation of these time expressions was as follows: morning at 6 am to 12 pm, noon from 12 to 3 pm, afternoon from 3 to 6 pm, evening from 6 to 10 pm, and night from 10 pm to 6 am. I had almost perfect agreement with my husband, except that he considered morning to start at 4 am. Interestingly, in Hebrew I would use “morning” to describe 4 am, i.e. “4 in the morning”, but because I don’t consider it a reasonable waking time, I made it part of the night. Indeed, this is “early morning”, a time expression I didn’t think of when I designed the survey. Many workers commented that they divide the time from dark to dawn into two or more different segments. Two workers from the Philippines indicated that the length of day and the length of night are equal, and that midnight marks the beginning of the new day, hence the morning. A worker from India commented that in their native language, there is a word for “early morning” used for the time range between 4 am to 6 am, though another Indian worker, possibly speaking a different native language, referred to this time as 12 am to 5 am. A third worker from India referred to 12 am to 4 am as “midnight”. That was surprising to me because I consider midnight as the exact time 12 am, although I realize I’m inconsistent with my interpretation of noon. Maybe it was clearer if it was more common to call it “midday” instead of “noon”.
Apart from the answers from Europe, which were diverse in terms of countries, the other regions were mostly dominated by a single country. The answers from North America were dominated by the US (93.6%), Asia and Pacific was dominated by India (85.6%), South America by Brazil (100%), and Africa and the Middle East only had 5 responses. It would also be interesting to study how the interpretation of time differs between states in the US, and in different times of the day, days of the week, and seasons. Do people tend to greet “good night” earlier in the day during the winter, when it gets dark early in the northern hemisphere, or is it always equivalent to “goodbye” after a certain hour, when “have a good day” doesn’t make much sense anymore? To solve the confusion, Americans often use the generic “have a good one” greeting, allowing the recipient to decide what “one” means in their own schedule.